
기술문서 : https://netflixtechblog.com/making-the-netflix-api-more-resilient-a8ec62159c2d
Making the Netflix API More Resilient
Maintaining high availability and resiliency for a system that handles a billion requests a day.
netflixtechblog.com
여느 서비스와 마찬가지로 넷플릭스 또한 유저들에게 최고의 스트리밍 서비스 경험을 제공하려면 항상 API 서버가 트래픽 처리가 가능한 상태를 유지하는 것이 중요합니다.
넷플릭스는 하루 평균 10억 건에 달하는 요청을 오고 이를 처리해야 하기 때문에 넷플릭스의 API 팀은 시스템의 고가용성과 탄력성을 유지하기 위해 API를 탄력적으로 만들기 위한 고민을 하였고 그 성과를 공유하였습니다.
API 탄력성을 보장하기 위한 원칙
API를 보다 탄력적으로 만들기 위해 노력하면서 넷플릭스가 생각한 몇 가지 원칙이 있습니다.
- 서비스 종속성 오류로 인해 회원의 사용자 경험이 중단되어서는 안 된다.
- API는 서비스 종속성 중 하나가 실패할 경우 자동으로 수정 조치를 위해야 한다.
- API는 15~30분 전, 어제, 지난주 등에 발생한 일 외에도 지금 일어나고 있는 일을 보여줄 수 있어야 한다.
스트리밍 상태를 유지하는 방법
위 원칙들을 보면 넷플릭스는 서버 장애가 발생하더라도 경험이 약간 저하되거나 개인화 수준이 떨어지더라도
유저들이 당장 스트리밍하는 영화 및 TV 프로그램을 계속해서 시청하는 것을 중요하게 생각하는 것을 알 수 있습니다.
이를 달성하기 위해 넷플릭스는 서비스 종속성이 실패할 때 적절한 대체 메커니즘이 시작될 수 있도록 각 호출의 결과를 추적하는 코드를 서비스 종속성에 대한 호출 시에 적용했고 서비스가 너무 자주 실패하는 것을 감지하면 서비스 호출을 중단하고 실패한 서비스를 복구할 시간을 주는 동시에 대체 응답을 제공합니다.
그런 다음 주기적으로 서비스에 대한 일부 호출을 통과하도록 하고, 성공하면 모든 호출에 대한 트래픽을 여는 방식을 사용했습니다.
이는 Michael Nygard의 책 "Release It!"에 나오는 CircuitBreaker 패턴에 기반한 방법으로
넷플릭스는 이 CircuitBreaker 패턴에서 조금 더 발전시켜 아래와 같이 풀백이 트리거 되는 상황을 추가하였습니다.
- 원격 서비스에 대한 요청이 초과되었을 때
- 서비스 종속성과 상호작용하는 데 사용되는 스레드 풀 및 제한된 작업 대기열 용량이 100% 일 때
- 서비스 종속성과 상호 작용하는 데 사용되는 클라이언트 라이브러리에서 예외가 발생했을 때
이러한 상황은 서비스 전체 오류 빈도에 영향을 미치며 오류 빈도가 정의된 임계값을 초과하면 해당 서비스에 대한 연결을 중단하고 원격 서비스와 통신을 하지 않고도 즉시 대체 서비스를 제공할 수 있도록 합니다.
연결 중단으로 대체되는 각 서비스는 다음 세 가지 접근 방식 중 하나를 사용합니다.
- 사용자 정의 폴백 : 서비스의 클라이언트 라이브러리가 호출할 수 있는 폴백 메서드를 제공하거나, 다른 경우에는 API 서버에서 로컬로 사용 가능한 데이터를 사용하여 폴백 응답을 생성하는 방법
- 자동 실패 : 폴백 메서드가 단순히 null을 반환하는 방법으로 이는 호출되는 서비스에서 제공하는 데이터가 요청 클라이언트로 다시 전송될 응답에 대해 선택 사항인 경우 유용하다.
- 빠른 실패 : 5xx 응답을 내보내는 방법으로 데이터가 필요하거나 적절한 대체 조치가 없는 경우 사용하는 방법. 이는 UX에 부정적인 영향을 미칠 수 있어 이상적인 방법은 아니지만 API 서버를 건강하게 유지하고 실패한 서비스를 다시 사용할 수 있을 때 시스템을 빠르게 복구할 수 있다는 장점이 있다.
사용자 정의 폴백으로 처리하는 것이 상황에 따라 최상의 사용자 경험을 제공하므로 가장 이상적인 방법이지만
서비스 종속성에 대해 완전한 대체 적용 범위를 유지하는 것도 어렵고 모든 상황을 고려해야 하기 때문에 현실적으로 모든 API에 적용하는 것은 불가능하다.
따라서 자동 실패 및 빠른 실패 접근 방식이 합리적인 대안이다.
이상적으로 모든 서비스 종속성은 상황에 따라 최상의 사용자 경험을 제공하므로 사용자 지정 폴백을 갖습니다. 이것이 우리의 목표이지만 많은 서비스 종속성에 대해 완전한 대체 적용 범위를 유지하는 것도 매우 어렵습니다. 따라서 자동 실패 및 빠른 실패 접근 방식이 합리적인 대안입니다.
실시간 통계 드라이브 소프트웨어 및 진단
위에서 넷플릭스는 서비스 종속성에 대한 요청을 추적하는 코드를 적용했다고 언급한 부분이 있는데
이 코드는 10초라는 롤링 기간 동안 각 서비스 종속성에 대한 요청을 계산합니다.
10초보다 오래된 요청 통계는 삭제되며 지난 10초 동안의 서비스 종속성 상태를 보여주는 대시보드를 만듭니다.
"지난 10초 동안의 서비스 종속성 상태를 보여주는 대시보드가 왜 필요하지?"라고 생각할 수도 있습니다.
넷플릭스의 API는 트래픽이 최고조에 달할 때 초당 약 20,000 요청을 수신합니다.
그럼 10초 동안 클라이언트에서 200,000개에 요청을 수신한다고 계산할 수 있고 이를 Upstream Service로 변환하면 1,000,000개 이상의 요청이 온다고 볼 수 있습니다.
넷플릿스는 10~15분 전에 일어난 일이 아니라 방금 일어난 일을 기준으로 의사 결정을 내리길 원하고 있기 때문에 10초로 설정하였고
이러한 실시간 통찰력은 회원이 직면하는 문제가 되기 전에 문제를 식별하고 대응하는 데도 도움이 됩니다.
( 물론 10초 범위를 넘어사는 추세를 식별할 수 있는 차트도 구현되어 있다고 합니다. )
CircuitBreaker의 동작
넷플릭스에서 API를 탄력적으로 만드는 방법을 설명했으니 실제로 이 방법이 제공할 수 있는 가치를 보여주는 예시를 소개하겠습니다.
넷플릭스에서 API가 특정 요청에 응답하기 위해 사용하는 데이터는 데이터베이스에 저장되지만 또한 공유 캐시에 Java 객체로 캐시 되는데
이러한 요청 중 하나를 받으면 API는 공유 캐시를 살펴보고 개체가 없으면 데이터베이스를 쿼리 하도록 동작하고 있습니다.
어느 날 API 때때로 완전히 채워지지 않은 공유 캐시에 Java 개체를 로드하는 버그가 발생했고 이로 인해 특정 장치에서 간헐적으로 문제가 발생하는 상황이 있었습니다.
문제를 발견한 후 이를 해결하기 전에 공유 캐시를 우회하고 데이터베이스로 직접 요청을 보내도록 바꾸었고
아래 차트처럼 캐시 적중률과 캐시를 비활성화시킨 후 적중률이 0으로 떨어지는 것을 확인하였습니다.
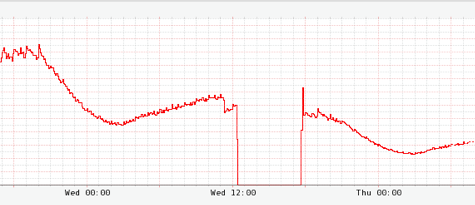
하지만 여기서 너무 많은 트래픽이 데이터베이스에 몰리면서 극심한 부하가 발생하였습니다.
다행스럽게도 데이터베이스 선택에 대한 사용자 지정 풀백이 구현되어 있었고
이는 데이터베이스 오류 시 로컬 쿼리 캐시를 확인하는 풀백 메서드를 호출하기 시작했습니다.
아래 차트는 대체 응답의 급증을 보여줍니다.
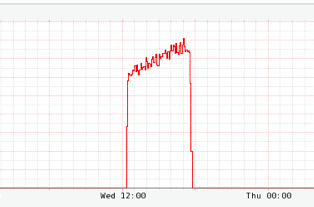
대체 쿼리 캐시에는 활성 데이터 세트의 대부분이 포함되어 있으므로 다음 차트에서 볼 수 있듯이 회원 경험에 대한 전반적인 영향이 매우 낮았습니다. 이는 전체 비디오 조회수에 최소한의 영향을 미칩니다. (빨간색 선은 이번주 초당 동영상 조회수, 검은색 선은 지난주와 동일한 수치입니다.)
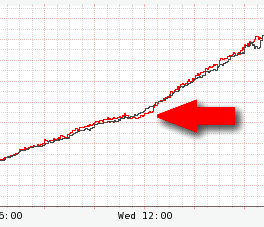
다음은 사고 당시 대시보드의 모습을 보여주는 발췌문입니다.
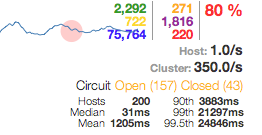
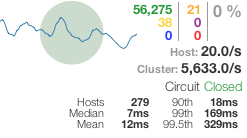
오른쪽 상단의 빨간색 80%는 데이터베이스 선택 회로의 전체 오류율을 나타내며, "열림" 및 "닫힘" 수는 대부분의 서버 인스턴스(200개 중 157개)가 대체 응답을 제공하고 있음을 나타냅니다. 파란색 개수는 데이터베이스 서버로 전송되지 않은 단락 된 요청 수입니다.
대시보드는 전형적인 녹색, 노란색, 빨간색 신호등 상태 페이지 패턴을 기반으로 하며 빠르게 검색할 수 있도록 설계되었습니다. 각 회선(현재 총 60개)에는 왼쪽에 통화량(원의 크기 - 클수록 트래픽이 더 많다는 의미)과 상태(원의 색상 - 녹색은 정상이고 빨간색은 서비스를 나타냄)를 인코딩하는 원이 있습니다. 문제가 있음). 스파크라인은 2분 롤링 기간 동안의 통화량을 나타냅니다. 단, 10초 기간 외부의 통계는 표시용으로만 사용되며 회로 차단기 논리를 고려하지 않습니다.
아래는 정상적인 상황에서의 대시보드입니다.
'기술문서 읽기' 카테고리의 다른 글
| ASGI에 대해서 (1) | 2024.02.08 |
|---|---|
| Rest API 디자인 모범 사례 (1) | 2024.01.28 |
| 데이터베이스 최적화하는 방법 11가지 (0) | 2024.01.14 |
| 대용량 데이터베이스에서 데이터를 효율적으로 Fetch 하는 방법 ( feat. Python Generator ) (0) | 2023.12.23 |
| PostgreSQL 공식문서 - Index (1) | 2023.12.21 |
기술문서 : https://netflixtechblog.com/making-the-netflix-api-more-resilient-a8ec62159c2d
Making the Netflix API More Resilient
Maintaining high availability and resiliency for a system that handles a billion requests a day.
netflixtechblog.com
여느 서비스와 마찬가지로 넷플릭스 또한 유저들에게 최고의 스트리밍 서비스 경험을 제공하려면 항상 API 서버가 트래픽 처리가 가능한 상태를 유지하는 것이 중요합니다.
넷플릭스는 하루 평균 10억 건에 달하는 요청을 오고 이를 처리해야 하기 때문에 넷플릭스의 API 팀은 시스템의 고가용성과 탄력성을 유지하기 위해 API를 탄력적으로 만들기 위한 고민을 하였고 그 성과를 공유하였습니다.
API 탄력성을 보장하기 위한 원칙
API를 보다 탄력적으로 만들기 위해 노력하면서 넷플릭스가 생각한 몇 가지 원칙이 있습니다.
- 서비스 종속성 오류로 인해 회원의 사용자 경험이 중단되어서는 안 된다.
- API는 서비스 종속성 중 하나가 실패할 경우 자동으로 수정 조치를 위해야 한다.
- API는 15~30분 전, 어제, 지난주 등에 발생한 일 외에도 지금 일어나고 있는 일을 보여줄 수 있어야 한다.
스트리밍 상태를 유지하는 방법
위 원칙들을 보면 넷플릭스는 서버 장애가 발생하더라도 경험이 약간 저하되거나 개인화 수준이 떨어지더라도
유저들이 당장 스트리밍하는 영화 및 TV 프로그램을 계속해서 시청하는 것을 중요하게 생각하는 것을 알 수 있습니다.
이를 달성하기 위해 넷플릭스는 서비스 종속성이 실패할 때 적절한 대체 메커니즘이 시작될 수 있도록 각 호출의 결과를 추적하는 코드를 서비스 종속성에 대한 호출 시에 적용했고 서비스가 너무 자주 실패하는 것을 감지하면 서비스 호출을 중단하고 실패한 서비스를 복구할 시간을 주는 동시에 대체 응답을 제공합니다.
그런 다음 주기적으로 서비스에 대한 일부 호출을 통과하도록 하고, 성공하면 모든 호출에 대한 트래픽을 여는 방식을 사용했습니다.
이는 Michael Nygard의 책 "Release It!"에 나오는 CircuitBreaker 패턴에 기반한 방법으로
넷플릭스는 이 CircuitBreaker 패턴에서 조금 더 발전시켜 아래와 같이 풀백이 트리거 되는 상황을 추가하였습니다.
- 원격 서비스에 대한 요청이 초과되었을 때
- 서비스 종속성과 상호작용하는 데 사용되는 스레드 풀 및 제한된 작업 대기열 용량이 100% 일 때
- 서비스 종속성과 상호 작용하는 데 사용되는 클라이언트 라이브러리에서 예외가 발생했을 때
이러한 상황은 서비스 전체 오류 빈도에 영향을 미치며 오류 빈도가 정의된 임계값을 초과하면 해당 서비스에 대한 연결을 중단하고 원격 서비스와 통신을 하지 않고도 즉시 대체 서비스를 제공할 수 있도록 합니다.
연결 중단으로 대체되는 각 서비스는 다음 세 가지 접근 방식 중 하나를 사용합니다.
- 사용자 정의 폴백 : 서비스의 클라이언트 라이브러리가 호출할 수 있는 폴백 메서드를 제공하거나, 다른 경우에는 API 서버에서 로컬로 사용 가능한 데이터를 사용하여 폴백 응답을 생성하는 방법
- 자동 실패 : 폴백 메서드가 단순히 null을 반환하는 방법으로 이는 호출되는 서비스에서 제공하는 데이터가 요청 클라이언트로 다시 전송될 응답에 대해 선택 사항인 경우 유용하다.
- 빠른 실패 : 5xx 응답을 내보내는 방법으로 데이터가 필요하거나 적절한 대체 조치가 없는 경우 사용하는 방법. 이는 UX에 부정적인 영향을 미칠 수 있어 이상적인 방법은 아니지만 API 서버를 건강하게 유지하고 실패한 서비스를 다시 사용할 수 있을 때 시스템을 빠르게 복구할 수 있다는 장점이 있다.
사용자 정의 폴백으로 처리하는 것이 상황에 따라 최상의 사용자 경험을 제공하므로 가장 이상적인 방법이지만
서비스 종속성에 대해 완전한 대체 적용 범위를 유지하는 것도 어렵고 모든 상황을 고려해야 하기 때문에 현실적으로 모든 API에 적용하는 것은 불가능하다.
따라서 자동 실패 및 빠른 실패 접근 방식이 합리적인 대안이다.
이상적으로 모든 서비스 종속성은 상황에 따라 최상의 사용자 경험을 제공하므로 사용자 지정 폴백을 갖습니다. 이것이 우리의 목표이지만 많은 서비스 종속성에 대해 완전한 대체 적용 범위를 유지하는 것도 매우 어렵습니다. 따라서 자동 실패 및 빠른 실패 접근 방식이 합리적인 대안입니다.
실시간 통계 드라이브 소프트웨어 및 진단
위에서 넷플릭스는 서비스 종속성에 대한 요청을 추적하는 코드를 적용했다고 언급한 부분이 있는데
이 코드는 10초라는 롤링 기간 동안 각 서비스 종속성에 대한 요청을 계산합니다.
10초보다 오래된 요청 통계는 삭제되며 지난 10초 동안의 서비스 종속성 상태를 보여주는 대시보드를 만듭니다.
"지난 10초 동안의 서비스 종속성 상태를 보여주는 대시보드가 왜 필요하지?"라고 생각할 수도 있습니다.
넷플릭스의 API는 트래픽이 최고조에 달할 때 초당 약 20,000 요청을 수신합니다.
그럼 10초 동안 클라이언트에서 200,000개에 요청을 수신한다고 계산할 수 있고 이를 Upstream Service로 변환하면 1,000,000개 이상의 요청이 온다고 볼 수 있습니다.
넷플릿스는 10~15분 전에 일어난 일이 아니라 방금 일어난 일을 기준으로 의사 결정을 내리길 원하고 있기 때문에 10초로 설정하였고
이러한 실시간 통찰력은 회원이 직면하는 문제가 되기 전에 문제를 식별하고 대응하는 데도 도움이 됩니다.
( 물론 10초 범위를 넘어사는 추세를 식별할 수 있는 차트도 구현되어 있다고 합니다. )
CircuitBreaker의 동작
넷플릭스에서 API를 탄력적으로 만드는 방법을 설명했으니 실제로 이 방법이 제공할 수 있는 가치를 보여주는 예시를 소개하겠습니다.
넷플릭스에서 API가 특정 요청에 응답하기 위해 사용하는 데이터는 데이터베이스에 저장되지만 또한 공유 캐시에 Java 객체로 캐시 되는데
이러한 요청 중 하나를 받으면 API는 공유 캐시를 살펴보고 개체가 없으면 데이터베이스를 쿼리 하도록 동작하고 있습니다.
어느 날 API 때때로 완전히 채워지지 않은 공유 캐시에 Java 개체를 로드하는 버그가 발생했고 이로 인해 특정 장치에서 간헐적으로 문제가 발생하는 상황이 있었습니다.
문제를 발견한 후 이를 해결하기 전에 공유 캐시를 우회하고 데이터베이스로 직접 요청을 보내도록 바꾸었고
아래 차트처럼 캐시 적중률과 캐시를 비활성화시킨 후 적중률이 0으로 떨어지는 것을 확인하였습니다.
하지만 여기서 너무 많은 트래픽이 데이터베이스에 몰리면서 극심한 부하가 발생하였습니다.
다행스럽게도 데이터베이스 선택에 대한 사용자 지정 풀백이 구현되어 있었고
이는 데이터베이스 오류 시 로컬 쿼리 캐시를 확인하는 풀백 메서드를 호출하기 시작했습니다.
아래 차트는 대체 응답의 급증을 보여줍니다.
대체 쿼리 캐시에는 활성 데이터 세트의 대부분이 포함되어 있으므로 다음 차트에서 볼 수 있듯이 회원 경험에 대한 전반적인 영향이 매우 낮았습니다. 이는 전체 비디오 조회수에 최소한의 영향을 미칩니다. (빨간색 선은 이번주 초당 동영상 조회수, 검은색 선은 지난주와 동일한 수치입니다.)
다음은 사고 당시 대시보드의 모습을 보여주는 발췌문입니다.
오른쪽 상단의 빨간색 80%는 데이터베이스 선택 회로의 전체 오류율을 나타내며, "열림" 및 "닫힘" 수는 대부분의 서버 인스턴스(200개 중 157개)가 대체 응답을 제공하고 있음을 나타냅니다. 파란색 개수는 데이터베이스 서버로 전송되지 않은 단락 된 요청 수입니다.
대시보드는 전형적인 녹색, 노란색, 빨간색 신호등 상태 페이지 패턴을 기반으로 하며 빠르게 검색할 수 있도록 설계되었습니다. 각 회선(현재 총 60개)에는 왼쪽에 통화량(원의 크기 - 클수록 트래픽이 더 많다는 의미)과 상태(원의 색상 - 녹색은 정상이고 빨간색은 서비스를 나타냄)를 인코딩하는 원이 있습니다. 문제가 있음). 스파크라인은 2분 롤링 기간 동안의 통화량을 나타냅니다. 단, 10초 기간 외부의 통계는 표시용으로만 사용되며 회로 차단기 논리를 고려하지 않습니다.
아래는 정상적인 상황에서의 대시보드입니다.
'기술문서 읽기' 카테고리의 다른 글
| ASGI에 대해서 (1) | 2024.02.08 |
|---|---|
| Rest API 디자인 모범 사례 (1) | 2024.01.28 |
| 데이터베이스 최적화하는 방법 11가지 (0) | 2024.01.14 |
| 대용량 데이터베이스에서 데이터를 효율적으로 Fetch 하는 방법 ( feat. Python Generator ) (0) | 2023.12.23 |
| PostgreSQL 공식문서 - Index (1) | 2023.12.21 |