
1. Introduction & Background (소개 및 등장 배경)
Apache Kafka의 공식 문서 소개문을 인용하면 아래와 같이 소개합니다.
수천 개의 회사에서 고성능 데이터 파이프라인, 스트리밍 분석, 데이터 통합을 위해 사용하는 오픈 소스 분산 이벤트 스트리밍 플랫폼
즉, Kafka는 분산 시스템에서 효율적으로 대용량 데이터 처리를 위해 Pub/Sub 구조로 동작하는 이벤트 스트리밍 플랫폼입니다.
Kafka가 등장한 배경은 LinkedIn에서 대용량 데이터(사용자 활동, 로그 등)의 데이터 파이프라인을 각 서버에서 end-to-end 구조로 처리를 하도록 되어 있었는데
서비스가 확장될수록 시스템 복잡도가 높아지고 유지 보수에 어려움이 증대되어 이 대용량 데이터를 중앙에서 효율적이고 안정적으로 처리할 수 있도록 하기 위해 Kafka를 개발하였다고 합니다.
2. Kafka Architecture (카프카 구조)
주요 용어와 기본 개념부터 살펴보면 아래와 같습니다.
Broker (브로커) : Broker는 Kafka 클러스터 내에서 중심적인 역할을 수행합니다. Producer에게 데이터를 수신, 저장하며 Consumer에게 데이터를전달하는 역할을 수행합니다. 한 클러스터 내에는 여러 브로커가 데이터를 분산 저장 및 처리함으로 고가용성을 보장하고 쉬운 확장을 제공합니다.
Topic (토픽) : Topic은 Kafka에서 데이터를 구분하는 주요 단위입니다. Producer는 특정 Topic에 데이터를 Publish하며 Consumer는 특정 토픽을 Subscribe하고 있다가 데이터를 소비합니다.
Partition (파티션) : Partition은 데이터를 분산하여 저장하는 물리적인 파일을 의미합니다. 한 개의 Topic은 한 개 이상의 Partition으로 구성될 수 있으며 저장된 데이터는 병렬 처리를 가능하게 해서 Kafka의 확장성과 성능을 향상시키는 주요 요소입니다.
Offset (오프셋) : 각 Partition에 저장되는 메시지는 offset을 가집니다. offset은 메시지가 게시된 순서를 의미하며 consumer가 어떤 메세지까지 소비했는지 offset을 기록함으로 다음으로 소비할 데이터들을 구분할 수 있는 기준이 됩니다.
Replica (레플리카) : Kafka에서 데이터의 안정성과 고가용성을 제공하기 위한 중요한 개념입니다. Replica는 서로 다른 Broker에 Partition의 복제본을 생성하여 시스템의 내결함성을 확보합니다.
Producer (프로듀서) : Producer는 데이터를 생성하고 Kafka 토픽으로 데이터를 Publish 하는 주체입니다.
Consumer (컨슈머) : Consumer는 Producer가 publish한 데이터를 소비하는 주체입니다. 특정 Topic을 Subscribe하고 있다가 데이터를 소비합니다.
위 개념들을 가지고 Kafka는 아래 그림과 같은 아키텍처를 가집니다.
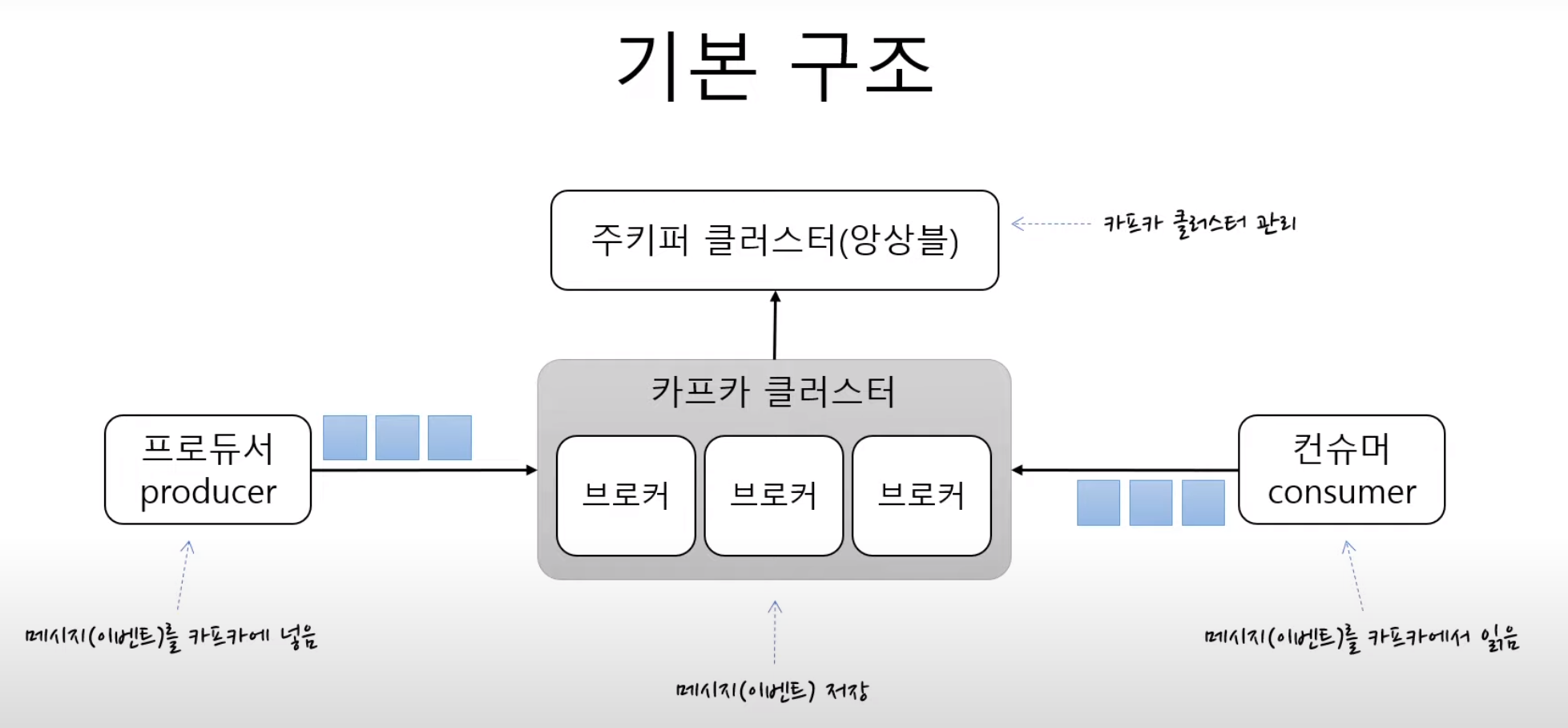
큰 범주에서 보면 간단히 아래와 같습니다.
- Producer가 Message(Event)를 Kafka에 게시합니다.
- 카프카 클러스터가 게시된 Message들을 효율적으로 관리하고 처리합니다.
- Consumer가 Message(Event)를 소비합니다.
즉, 분산 시스템에서 대용량 데이터들이 각각의 파이프라인을 가지면 운영적인 측면이나 기술적인 측면에서 까다로움이 많기 때문에 모든 대용량 데이터들을 Kafka라는 길을 통해서 관리하는 구조입니다.
3. How does Kafka ensure good performance? (Kafka가 좋은 성능을 보장하는 방법)
kafka에서 좋은 성능을 보장하는 방법은 다양한 것들이 있는데
대표적으로 아래 3가지를 설명하겠습니다.
- Broker의 업무 단순화
보통의 메세지 브로커의 경우 메시지 필터링이나 메시지 재전송과 같은 일들을 브로커가 담당하는데
Kafka Broker는 위 같은 처리를 온전히 Producer와 Consumer에게 맡기기 때문에 상대적으로 하는 일이 적어 좋은 성능을 보장합니다.
- Batch 처리
Kafka는 batch를 활용하여 많은 데이터를 묶어서 Publish 하거나 Consume 할 수 있기 때문에 적절히 활용하면 높은 처리량을 보장할 수 있습니다. 실제 옵션으론 배치의 크기를 지정하는 batch.size나 배치가 가득 차지 않아도 일정 시간이 지나면 전송할 수 있도록 하는 linger.ms 옵션과 같이 batch에 관련된 옵션을 상황에 맞게 조정하여 높은 성능을 낼 수 있습니다.
- 다수의 Partition을 활용한 병렬처리
1개의 Topic에 대해 여러 Partition을 두어 병렬 처리가 가능합니다.
많은 데이터가 들어오더라도 Producer는 라운드로빈 방식으로 메시지를 게시할 Partition을 정할 수 있으므로 메시지 처리에 대한 병목 현상을 방지하고 효율적으로 데이터를 처리할 수 있습니다.
하지만 Partition을 여러 개로 나누어 병렬 처리 효과를 얻으면 데이터의 순서를 보장하지 않기 때문에 주의해야 합니다.
쉽게 말해, 같은 Topic이더라도 각 Partition은 독립적으로 동작하고 이로 인해 각 Partition마다 저장하고 있는 메시지가 모두 다르기 때문에 메시지에 대한 순서가 보장되지 않습니다.
예를들어, 사용자 로깅 Topic에서 2개 이상의 Partition을 사용한다고 가정했을때 특정 리소스를 수정한 이벤트가 A Partition에 게시되고 특정 리소스를 삭제한 이벤트가 B Partition에 게시되었을 때 올바른 로깅 순서는 A Partition에 있는 수정 이벤트를 처리한 다음 B Partition에 있는 삭제 이벤트를 처리하는 것이지만 실제로는 B Partition에 있는 삭제 이벤트가 먼저 처리되어 삭제된 후 수정되었다고 로그가 기록될 수 있습니다.
이를 해결하기 위해선 순서가 중요한 토픽에 대해서는 1개의 파티션을 사용하거나 파티션 key 를 지정해주어 순서를 보장받을 수 있습니다.
하지만 두 방법 모두 병렬 처리의 이점을 상당 부분 잃어버리기 때문에 토픽의 특징을 고려하여 적절히 운영하는 것이 중요합니다.
4. How Kafka ensures high availability (Kafka가 고가용성을 보장하는 방법)
Kafka는 각 Partition마다 Replica를 두어 고가용성을 보장합니다.
Replica는 Partition의 복제본이며 최소 몇 개의 브로커에 replica를 생성할 건지에 대한 옵션인 replication factor의 값에 따라 생성됩니다.
replica는 Leader(리더)와 Follower(팔로워) 개념이 있는데 각 역할은 아래와 같습니다.
Leader : 메시지 게시(write)와 소비(read)를 담당함
Follower : Leader의 데이터를 복제(copy) 함
간단히 말해 모든 데이터 게시와 소비는 Leader를 통해 이루어지며 Follower들은 장애를 대비해 Leader 메시지들을 복제해두는 역할만을 담당합니다.
그래서 만약 Leader가 속한 Broker에 장애가 발생하더라도 다른 Broker에 있는 Follower 중 하나가 Leader로 선출되어 고가용성을 확보할 수 있도록 동작합니다.
Leader로 선출되는 기준
ISR(In-Sync Replicas)이라는 Leader와 동기화된 Follower들을 정의하고 있는 집합이 있는데 이를 통해 가장 최근에 Leader와 동기화 된 Follower를 찾아 리더로 선출합니다.
Reference
'개발공부' 카테고리의 다른 글
| 동시성 이슈가 발생하는 이유 (0) | 2024.06.26 |
|---|---|
| Python List 내부 뜯어보기 (0) | 2024.02.18 |
| Python에서 N+1을 해결하는 방법 (SQLAlchemy) (0) | 2024.01.28 |
| 비밀번호를 어떻게 암호화해야 안전할까? (2) | 2024.01.07 |
| Debezium이란 무엇인가? (0) | 2023.12.21 |